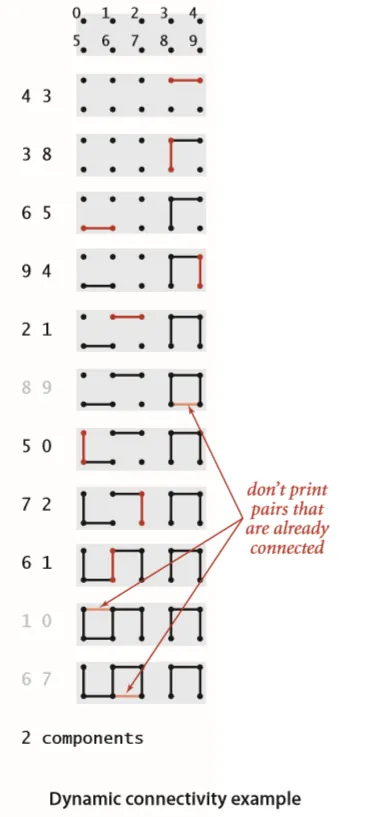
动态连通性 问题说明:问题的输入是一列整数对,其中每个整数都表示一个某种类型的对象,一对整数 p q 可以被理解为“ p 和 q 是相连的”。我们假设“相连”是一种等价关系,这也就意味着它具有:
自反性:p 和 p是相连的; 对称性:如果 p 和 q 是相连的,那么 q 和 p 也是相连的; 传递性:如果 p 和 q 是相连的且 q 和 r 是相连的,那么 p 和 r 也是相连的。 等价关系能够将对象分为多个等价类。在这里,当且仅当两个对象相连时它们才属于同一个等价类。我们的目标是编写一个程序来过滤掉序列中所有无意义的整数对(两个整数对均来自于同一个等价类中)。换句话说,当程序从输入中读取了整数对 p q 时,如果已知的所有整数对都不能说明 p 和 q 是相连的,那么则将这一对整数写入到输出中。如果已知的数据可以说明 p 和 q 是相连的,那么程序应该忽略 p q 这对整数对并继续处理输入的下一对整数。
上图用一个例子说明了这个过程,而我们需要设计一个数据结构来保存已知的所有整数对的足够多的信息,并用他们来判断一对新对象是否是相连的。我们将这个问题通俗地叫做动态连通性问题。这个问题一般有以下几种应用:
网络(计算机网络架设、电子电路中的触点、社交网络关系)
变量名等价性(某些编程环境下的别名 alias)
数学集合 (更高的抽象层次,这里不展开讲了)
在这里我们统一一下术语:将对象称为触点 ,将整数对称为连接 ,将等价类称为连通分量 或简称为分量 。
设计一份 API 来封装所需的基本操作:初始化、连接两个触点、判断包含某个触点的分量、判断两个触点是否存在于同一个分量之中以及返回所有分量的数量:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class UF public UF (int N) public void union (int p, int q) public int find (int p) public boolean connected (int p, int q) public int count ()
基本实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class UF private int [] id; private int count; public UF (int N) new int [N];for (int i = 0 ; i < N; i++)public void union (int p, int q) public int find (int p) public boolean connected (int p, int q) return find(p) == find(q);public int count () return count;
quick-find 算法 一种方法是保证当且仅当 id[p] 等于 id[q] 时 p 和 q 是连通的。换句话说,在同一个连通分量当中的所有触点在 id[] 中的值必须全部相同。数组中保存的值,即为当前触点(索引)对应的分量标识符。当对两个非连通触点进行连接时,则需要遍历整个数组,将所有的和 id[p] 相等的元素的值变为 id[q] 的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public void union (int p, int q) int pId = find(p);int qId = find(q);if (pId != qId) {for (int i = 0 ; i < id.length; i++) {if (id[i] == pId) {public int find (int p) return id[p];
不难看出 quick-find 算法中 find() 的操作速度是很快的,因为它只需要访问 id[] 数组一次。但这一般无法处理大型问题,因为对于每一对输入 union() 都需要扫描整个 id[] 数组。我们需要寻找更好的算法。
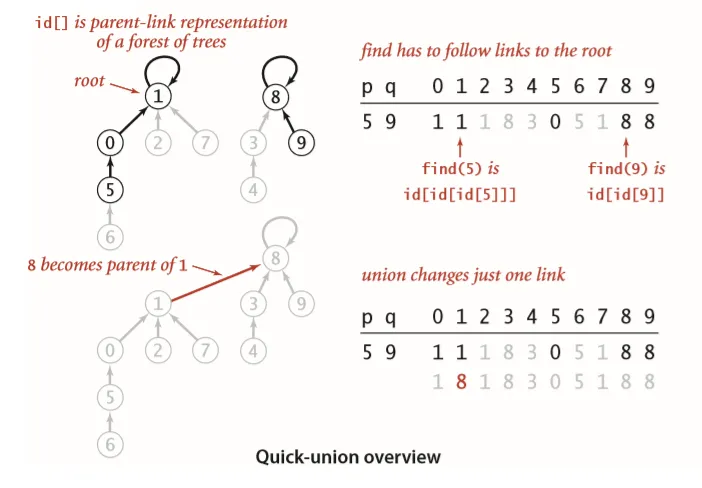
quick-union 算法 我们现在尝试提升 union() 的速度,这次对 id[] 数组的值赋予不同的意义,每个触点(索引)对应的值不再直接就是分量了,而是指向另外一个触点(索引),而当触点指向自己本身(索引)时,才是真正的分量。可以想象这些连通分量,像一棵树一样连接在一起,一层一层向上追溯,而根节点即为分量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public void union (int p, int q) int pRoot = find(p);int qRoot = find(q);if (pRoot != qRoot) {public int find (int p) while (p != id[p])return p;
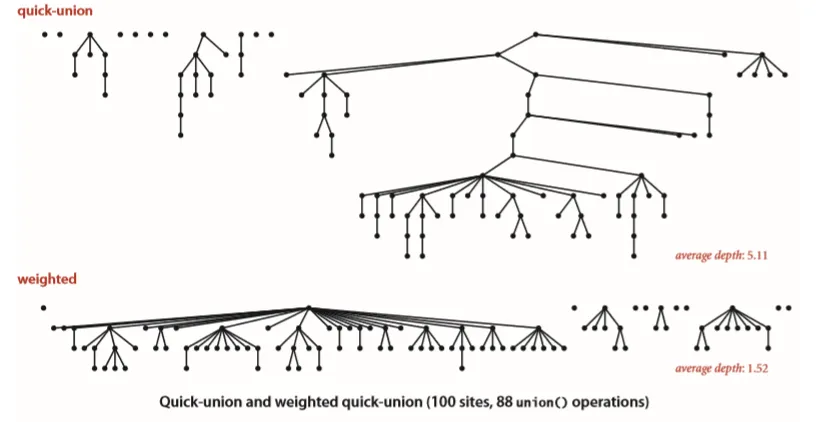
加权 quick-union 算法 定义:一颗树的大小是它的节点的数量。树中的一个节点的深度是它到根节点的路径上的链接数。树的高度是它所有节点中的最大深度
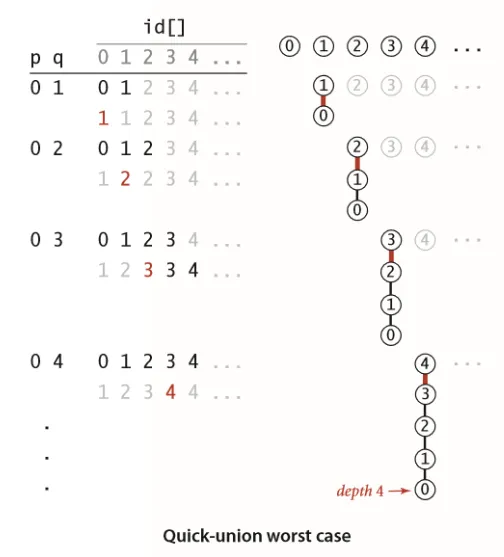
命题:quick-union 算法中的 find() 方法访问数组的次数为1加上给定触点所对应的节点的深度的两倍。
可以看出,当 union() 在某些特定场景下,构造出的树的深度过大,会导致这种算法的查找性能并不好。
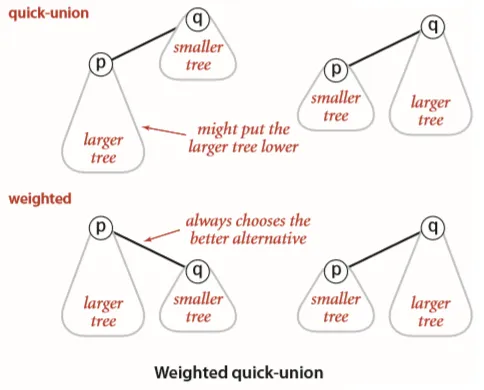
我们只需要稍加改进,就可以优化 quick-union 算法:额外使用一个数组,来记录树的大小,避免大树连接到小树根节点造成树的深度过深。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 public class UF private int [] id; private int count; private int [] sz; public UF (int N) new int [N];for (int i = 0 ; i < N; i++) {1 ; public void union (int p, int q) int pRoot = find(p);int qRoot = find(q);if (pRoot != qRoot) {if (sz[pRoot] > sz[qRoot]) {else {public int find (int p) while (p != id[p])return p;public boolean connected (int p, int q) return find(p) == find(q);public int count () return count;